二次元データの区分けが楽々できるパッケージの紹介です。区分け後のデータはパッケージ収録されている「bi_scale_fill」コマンドと凡例を作成する「bi_legend」コマンドを組み合わせて「ggplot2」パッケージでの利用が可能です。
実行コマンドではe-Statで公開の2019年各都道府県の総人口(A1101)と世帯主収入(L3111011)を使用した区分けデータの作成例と「ggplot2」パッケージでの使用例を紹介します。
本パッケージは各コマンドの「dim」オプションを適切に設定することです。ミスがないように専用の変数を設定するのが良いかと思います。
パッケージバージョンは1.0.0。実行コマンドはwindows 11のR version 4.1.3で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("biscale")実行コマンド
詳細はコマンド、各パッケージのヘルプを確認してください。
#パッケージの読み込み
library("biscale")
###データ例の作成#####
#日本地図データにe-Statで公開の2019年各都道府県の総人口(A1101)と
#世帯主収入(L3111011)データを付与
#tidyverseパッケージがなければインストール
if(!require("tidyverse", quietly = TRUE)){
install.packages("tidyverse");require("tidyverse")
}
JapanGrid <- tibble(
#各都道府県の位置
x = c(15.9, 15.5, 16, 16, 15.7, 15.7, 16, 15, 15, 14.7, 14.7, 15,
15, 13.7, 14, 14, 12.7, 13, 13, 11.7, 11.7, 12, 12, 11, 11,
10, 10, 10, 9, 9, 8, 8, 7, 7, 7.5, 7.5, 6.5, 6.5, 6, 4.5, 4.5,
4.5, 3.5, 3.5, 3.5, 2.5, 2),
y = c(12.9, 10.5, 9.5, 8.5, 7.5, 6.5, 5.5, 9.5, 8.5, 7.5, 6.5, 5.5,
4.5, 6.5, 5.5, 4.5, 6.5, 5.5, 4.5, 7.5, 6.5, 5.5, 4.5, 5.5,
4.5, 6, 5, 4, 5.5, 4.5, 6, 5, 6, 5, 3.5, 2.5, 3.5, 2.5, 5.5, 5, 4,
3, 5, 4, 3, 5, 2),
#widthとheightはタイルの大きさ
width = c(2.5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1),
height = c(2.5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1),
name = c("北海道", "青森県", "岩手県", "宮城県", "福島県",
"茨城県", "千葉県", "秋田県", "山形県", "新潟県",
"栃木県", "埼玉県", "東京都", "群馬県", "山梨県",
"神奈川県", "富山県", "長野県", "静岡県", "石川県",
"福井県", "岐阜県", "愛知県", "滋賀県", "三重県",
"京都府", "奈良県", "和歌山県", "兵庫県", "大阪府",
"鳥取県", "岡山県", "島根県", "広島県", "香川県", "徳島県",
"愛媛県", "高知県", "山口県", "福岡県", "大分県", "宮崎県",
"佐賀県", "熊本県", "鹿児島県", "長崎県", "沖縄県"),
population = c(5250000, 1246000, 1227000, 2306000, 1846000, 2860000,
6259000, 966000, 1078000, 2223000, 1934000, 7350000,
13921000, 1942000, 811000, 9198000, 1044000, 2049000,
3644000, 1138000, 768000, 1987000, 7552000, 1414000,
1781000, 2583000, 1330000, 925000, 5466000, 8809000,
556000, 1890000, 674000, 2804000, 956000, 728000,
1339000, 698000, 1358000, 5104000, 1135000, 1073000,
815000, 1748000, 1602000, 1327000, 1453000),
income = c(445412, 357657, 407047, 394064, 442343, 464558, 522793,
388059, 432703, 442096, 437393, 604915, 541315, 369030,
434731, 481065, 369259, 420433, 431561, 466789, 398272,
448691, 426601, 473239, 484285, 354736, 453705, 445259,
444813, 408470, 345036, 386071, 397061, 445291, 452776,
403862, 399411, 379741, 418939, 429057, 381563, 343338,
474686, 374987, 425488, 433126, 290871))
########
#2変数の基準でデータを区分する:bi_classコマンド
#分割基準:styleオプション;"quantile","equal","fisher","jenks"
#分割数:dimオプション;2-4の範囲
PlotData <- bi_class(.data = JapanGrid,
x = population, y = income,
style = "quantile", dim = 3)
#「ggplot2」パッケージで利用する凡例を作成:bi_legendコマンド
#カラーパレットを指定:palオプション;"Bluegill","BlueGold","BlueOr",
#"BlueYl","Brown","Brown2","DkBlue","DkBlue2","DkCyan","DkCyan2",
#"DkViolet""DkViolet2","GrPink","GrPink2","PinkGrn","PurpleGrn","PurpleOr"
#「ggplot2」パッケージでplot in plotのためにggplot2::ggplotGrobコマンドを利用
GG_legend <- ggplotGrob(bi_legend(pal = "Brown",
dim = 3,
xlab = "A1101_総人口",
ylab = "L3111011_世帯主収入",
size = 8))
#プロット
ggplot(data,
aes(x = x, y = y, width = width, height = height)) +
geom_tile(aes(fill = bi_class),
color = "grey", show.legend = FALSE) +
geom_text(aes(label = name), size = 2.6) +
#塗りつぶしを適切におこなう:bi_scale_fillコマンド
bi_scale_fill(pal = "Brown", dim = 3) +
coord_fixed(ratio = 1) +
theme_void() +
#凡例を追加:ggplot2::annotation_customコマンド
annotation_custom(grob = GG_legend,
xmin = 3, xmax = 8,
ymin = 8, ymax = 14)出力例
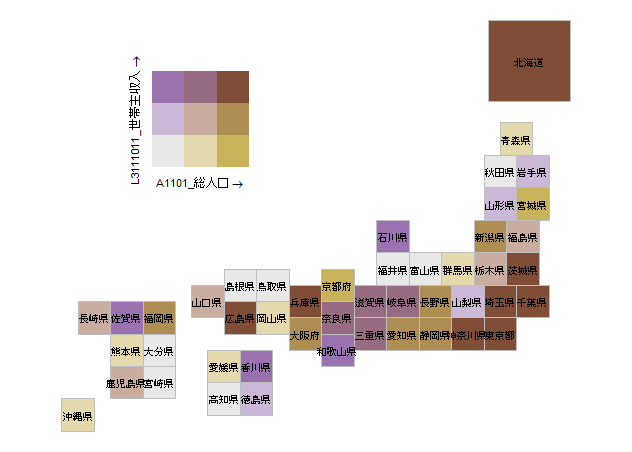
少しでも、あなたの解析が楽になりますように!!