テキストマイニングにはRMecabが大変便利です。ただ、単一文字の分布調査は少し工夫が必要です。そんな問題の解決となるパッケージの紹介です。
パッケージには文字列を分解するのに便利なコマンドが多数収録されています。その中から、単一文字や複数単語で構成される文字ベクトルの「単一文字および単語を構成する単一文字」の分布を調査する「ttMatrixコマンド」「pwMatrixコマンド」を紹介します。
また、おまけとして「ttMatrixとpwMatrixコマンドの組み合わせ処理で各単語内の文字の分布数を調査」するコマンドを紹介します。
パッケージのバージョンは0.9.7。実行コマンドはR version 4.2.2で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
#パッケージのインストール
install.packages("qlcMatrix")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("qlcMatrix")
###データ例の作成#####
TestData <- c("a", rep("あ", 3), "i", "い")
[1] "a" "あ" "あ" "あ" "i" "い"
TestString <- c("からだにいいこと", "Rでいいこと")
[1] "からだにいいこと" "Rでいいこと"
########
#各文字列の分布状況を確認:ttMatrixコマンド
#結果形式を指定:simplifyオプション;FALSEでlist class,TRUEでngCMatric class
ttMatrix(TestData, simplify = FALSE)
$M
4 x 6 sparse Matrix of class "ngCMatrix"
[1,] | . . . . .
[2,] . . . . | .
[3,] . | | | . .
[4,] . . . . . |
$rownames
[1] "a" "i" "あ" "い"
#simplify:TRUE
ttMatrix(TestData, simplify = TRUE)
4 x 6 sparse Matrix of class "ngCMatrix"
a あ あ あ i い
a | . . . . .
i . . . . | .
あ . | | | . .
い . . . . . |
#各単語を構成する文字列の分布状況を確認:pwMatrixコマンド
単語間の区切りを設定:gap.lengthオプション;区切り回数,gap.symbolオプション;区切りのシンボル
pwMatrix(TestString, simplify = TRUE, gap.length = 2,
gap.symbol = " ", sep = "")
15 x 2 sparse Matrix of class "ngCMatrix"
からだにいいこと Rでいいこと
か | .
ら | .
だ | .
に | .
い | .
い | .
こ | .
と | .
. .
. .
R . |
で . |
い . |
い . |
こ . |
と . |
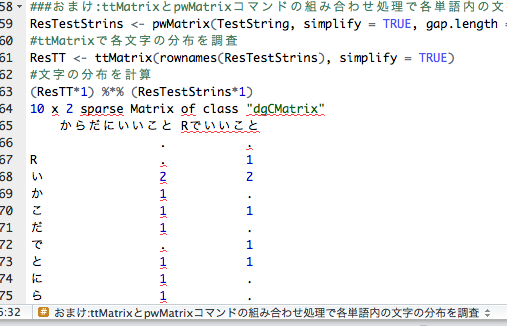
###おまけ:ttMatrixとpwMatrixコマンドの
###組み合わせ処理で各単語内の文字の分布を調査#####
ResTestStrins <- pwMatrix(TestString, simplify = TRUE,
gap.length = 2, gap.symbol = " ", sep = "")
#ttMatrixで各文字の分布を調査
ResTT <- ttMatrix(rownames(ResTestStrins), simplify = TRUE)
#文字の分布を計算
(ResTT*1) %*% (ResTestStrins*1)
10 x 2 sparse Matrix of class "dgCMatrix"
からだにいいこと Rでいいこと
. .
R . 1
い 2 2
か 1 .
こ 1 1
だ 1 .
で . 1
と 1 1
に 1 .
ら 1 .少しでも、あなたの解析が楽になりますように!!