
docxファイルやxlsxファイルはxlmファイル群をzipで圧縮した構造です。解凍してしまえばXMLパッケージで読み込むことができます。そこで、XMLパッケージの利用例としてxlsxファイルを読み込むコマンド例を作成しました。
XMLパッケージの利用例を目的に作成したので処理速度が遅いですが、10,000程度のデータであれば約1分以内に処理できるので、我慢できる範囲かと思います。
なお、sapplyとxpathSApplyでデータを取得している箇所を工夫すると読み込み速度が快適になると思います。ぜひ、挑戦してみてください。
パッケージを利用して快適にxlsxファイルを読み込みたい方は下記記事をどうぞ。
・openxlsxパッケージの紹介
https://www.karada-good.net/analyticsr/r-338/
・XLConnectパッケージの紹介
https://www.karada-good.net/analyticsr/r-51/
・WriteXLSパッケージの紹介
https://www.karada-good.net/analyticsr/r-138/
参考にXMLパッケージで読み込むdocxファイルの例です。
https://www.karada-good.net/analyticsr/r-368/
実行コマンドはR version 3.2.2で確認しています。
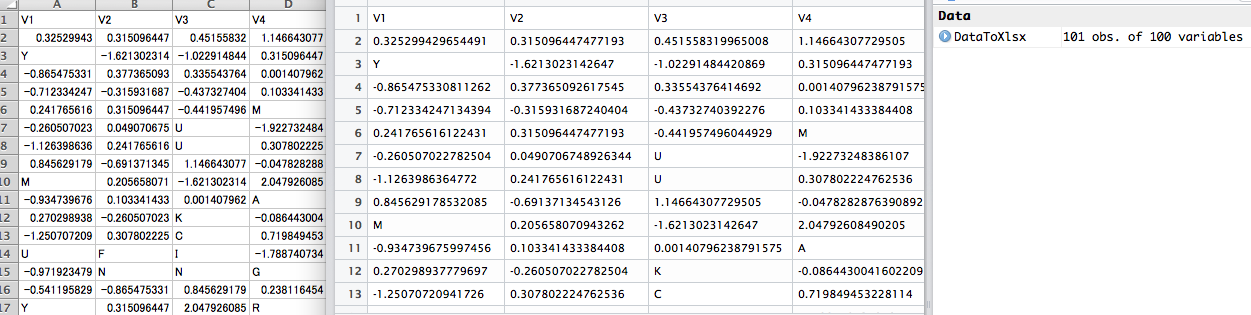
オリジナルのxlsxとR内での表示
実行コマンド
詳細はコメント、コマンドのヘルプを確認してください。
[code language="R"]
#必要パッケージの読み込み
library("tcltk")
install.packages("XML")
library("XML")
#ファイルを選択
file <- paste0(as.character(tkgetOpenFile(title = "ファイルを選択",
filetypes = '{"ファイル" {".xlsx"}}',
initialfile = c("*.xlsx"))))
#読み込むシート番号を設定
SheetId <- 1
#一時フォルダを作成
tmp <- tempfile()
#xlsxファイルを解凍
unzip(file, exdir = tmp)
#文字情報のxmlファイルパスを取得
xmlStringsPath <- file.path(tmp, "xl", "sharedStrings.xml")
#シート情報のxmlファイルパスを取得
xmlSheetPath <- file.path(tmp, "xl", "worksheets", paste0("sheet", SheetId, ".xml"))
#文字情報のxmlを読み込み
StringsData <- xmlParse(xmlStringsPath)
#文字情報の取得,namespaceを設定するのがポイント
GetStringsData <- xpathSApply(StringsData, "//x:si", namespaces = "x", xmlValue)
#シート情報のxmlを読み込み
SheetData <- xmlParse(xmlSheetPath)
#列情報を取得,<row>のspans属性値を取得して最大値を取得
GetRC <- xpathSApply(SheetData, "//x:row", namespaces = "x", xmlGetAttr, "spans")
ColRange <- unlist(strsplit(unique(GetRC), ":"))
ColRange <- type.convert(ColRange[2])
#列番号取得用のアルファベット配列を作成
GetColNo <- LETTERS
for(m in seq(ceiling(ColRange/26))){
GetColNo <- c(GetColNo, paste0(LETTERS[m], LETTERS))
}
#tempフォルダの削除
unlink(tmp, recursive = TRUE)
#行列番号の取得
DataRowColNO <- sapply(list(xmlChildren(SheetData))[[1]], function(x) xpathSApply(x, "//x:c", namespaces = "x", xmlGetAttr, "r"))
#行番号の取得
DataRowNO <- type.convert(gsub("[[:alpha:]]", "", DataRowColNO))
#列番号の数値化・取得
DataColNO <- match(gsub("[[:digit:]]", "", DataRowColNO), GetColNo)
#データ属性の取得
DatatValue <- sapply(list(xmlChildren(SheetData))[[1]], function(x) xpathSApply(x, "//x:c", namespaces = "x", xmlGetAttr, "t"))
#データの取得
RawData <- type.convert(sapply(xpathSApply(SheetData, "//x:row", namespaces = "x"),
function(x) xpathSApply(x, "//x:v", namespaces = "x", xmlValue))[, 1])
#属性に合わせてテキストを取得し該当箇所を置換
RawData[DatatValue == "s"] <- GetStringsData[RawData[DatatValue == "s"] + 1]
#データを結合
ExData <- data.frame(DataRowNO, DataColNO, I(RawData))
#ExDataを元にdata.frameを作成
#データ格納用のmatrixを作成
MasterMatrix <- matrix(NA, nrow = max(ExData[, 1]), ncol = max(ExData[, 2]))
for(n in seq(nrow(ExData))){
MasterMatrix[ExData[n, 1], ExData[n, 2]] <- ExData[n, 3]
}
#必要があればデータの整形
#1行目を列名にする
#colnames(MasterMatrix) <- MasterMatrix[1, ]
#MasterMatrix <- MasterMatrix[-1, ]
#データのdata.frame化
DataToXlsx <- as.data.frame(MasterMatrix)
#必要のないデータを削除
#rm(list = ls()[ls() != "DataToXlsx"])
#おまけ,DataToXlsxを作業ディレクトリにcsvで出力
#mac用
write.csv(DataToXlsx, "DataToXlsx.csv", quote = FALSE,
row.names = FALSE, fileEncoding = "CP932", eol = "\r\n")
#windows用
write.csv(DataToXlsx, "DataToXlsx.csv", quote = FALSE, row.names = FALSE)少しでも、あなたの解析が楽になりますように!!

