記述統計作成に大変便利なパッケージの紹介です。カテゴリ変数と量的変数を分けて結果を出力する「dtable」コマンドはオススメです。
また、パッケージにはデータ変数をclassごとにまとめて出力する「dclass」コマンド、指定した数値classに属する全データを要約する「dnumeric」コマンド、指定した成分名と長さで空のリストを作成する「create_list」コマンドが収録されています。
なお、パッケージバージョンが0.0.1で一部のヘルプが実装されていません。今後のバージョンアップに期待です。
実行コマンドはR version 3.2.2で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
#パッケージのインストール
install.packages("devtools")
devtools::install_github("gitronald/demotables")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
##パッケージの読み込み
library("demotables")
###データ例の作成#####
n <- 20
TestData <- data.frame(AsisData = I(sample(paste0("ASIS", 1:3), n, replace = TRUE)),
NumData = rnorm(n),
FacData = sample(paste0(LETTERS[1:24]), n, replace = TRUE),
IntData = sample(1:10, n, replace = TRUE),
LogiData = sample(c(TRUE, FALSE), n, replace = TRUE),
chrData = sample(c("a", "b", "c", "d"), n, replace = TRUE))
TestData[ ,6] <- as.character(TestData[ ,6])
#構造確認
str(TestData)
'data.frame': 20 obs. of 6 variables:
$ AsisData:Class 'AsIs' chr [1:20] "ASIS2" "ASIS2" "ASIS1" "ASIS1" ...
$ NumData : num 0.0407 1.4073 -1.2281 -0.4624 -0.0478 ...
$ FacData : Factor w/ 13 levels "A","B","C","I",..: 5 10 3 7 4 6 1 12 2 7 ...
$ IntData : int 6 1 2 3 9 2 6 5 9 4 ...
$ LogiData: logi TRUE TRUE TRUE TRUE TRUE TRUE ...
$ chrData : chr "d" "d" "d" "d" ...
########
#カテゴリ変数と量的変数を分けて記述統計を出力:dtableコマンド
#出力の体裁を整える:neatオプション
#クラスごとに結果を格納:as.listオプション
#as.listオプションの設定に関わらず,結果はリスト成分にデータフレームで格納されます
#AsIs classは省略されるようです
Result <- dtable(TestData, neat = TRUE, as.list = FALSE)
#構造を確認
str(Result)
List of 2
$ Freq:'data.frame': 28 obs. of 5 variables:
#内容を省略
$ Desc:'data.frame': 2 obs. of 15 variables:
..$ dataset : Factor w/ 1 level "data1": 1 1
#内容を省略
#結果を表示
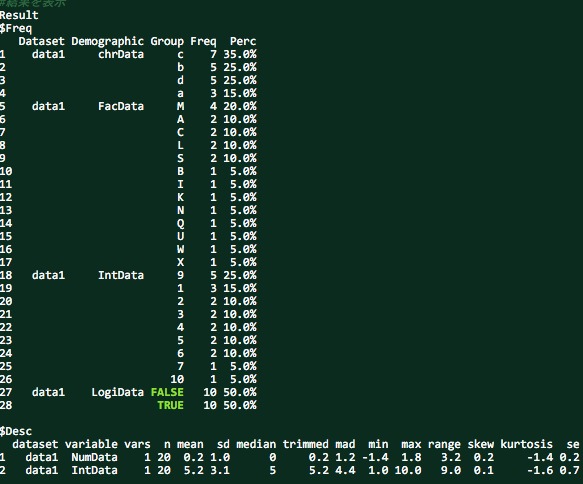
Result
$Freq
Dataset Demographic Group Freq Perc
1 data1 chrData c 7 35.0%
2 b 5 25.0%
3 d 5 25.0%
4 a 3 15.0%
5 data1 FacData M 4 20.0%
6 A 2 10.0%
7 C 2 10.0%
8 L 2 10.0%
9 S 2 10.0%
10 B 1 5.0%
11 I 1 5.0%
12 K 1 5.0%
13 N 1 5.0%
14 Q 1 5.0%
15 U 1 5.0%
16 W 1 5.0%
17 X 1 5.0%
18 data1 IntData 9 5 25.0%
19 1 3 15.0%
20 2 2 10.0%
21 3 2 10.0%
22 4 2 10.0%
23 5 2 10.0%
24 6 2 10.0%
25 7 1 5.0%
26 10 1 5.0%
27 data1 LogiData FALSE 10 50.0%
28 TRUE 10 50.0%
$Desc
dataset variable vars n mean sd median trimmed mad min max range skew kurtosis se
1 data1 NumData 1 20 0.2 1.0 0 0.2 1.2 -1.4 1.8 3.2 0.2 -1.4 0.2
2 data1 IntData 1 20 5.2 3.1 5 5.2 4.4 1.0 10.0 9.0 0.1 -1.6 0.7
#データの構造をclassごとに表示:dclassコマンド
#結果をlistで出力:as.listオプション
dclass(TestData, as.list = TRUE)
$AsIs
variable class
1 AsisData AsIs
$character
variable class
6 chrData character
$factor
variable class
3 FacData factor
$integer
variable class
4 IntData integer
$logical
variable class
5 LogiData logical
$numeric
variable class
2 NumData numeric
#数値classに属する全データの要約:dnumericコマンド
#指定したclassに属する全データが処理されます
dnumeric(TestData, "IntData")
dataset variable vars n mean sd median trimmed mad min max range skew kurtosis se
1 TestData IntData 1 20 5.2 3.1 5 5.2 4.4 1 10 9 0.1 -1.6 0.7
#指定した成分名と長さで空のリストを作成:create_listコマンド
create_list(c("a", "b"), 2)
$a
$a[[1]]
NULL
$a[[2]]
NULL
$b
$b[[1]]
NULL
$b[[2]]
NULL少しでも、あなたの解析が楽になりますように!!