数値や文字の整形にはformatコマンドなどを利用するのが手ですが、数値と文字を含む配列では最長オブジェクトの桁数分の空白が挿入されてしまいます。面倒な工夫もなく、体裁を整形することができるパッケージの紹介です。
パッケージバージョンは0.0.1。実行コマンドはR version 3.2.3で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
#パッケージのインストール
install.packages("pacman")
pacman::p_load_gh("trinker/digit")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("digit")
#文字列の体裁を整える:fコマンド
#小数点の表示数:digitsオプション
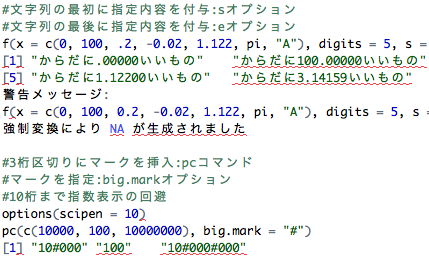
#文字列の最初に指定内容を付与:sオプション
#文字列の最後に指定内容を付与:eオプション
f(x = c(0, 100, .2, -0.02, 1.122, pi, "A"), digits = 5, s = "からだに", e = "いいもの")
[1] "からだに.00000いいもの" "からだに100.00000いいもの" "からだに.20000いいもの" "からだに-.02000いいもの"
[5] "からだに1.12200いいもの" "からだに3.14159いいもの" "からだにNAいいもの"
警告メッセージ:
f(x = c(0, 100, 0.2, -0.02, 1.122, pi, "A"), digits = 5, s = "からだに", で:
強制変換により NA が生成されました
#3桁区切りにマークを挿入:pcコマンド
#マークを指定:big.markオプション
#10桁まで指数表示の回避
options(scipen = 10)
pc(c(10000, 100, 10000000), big.mark = "#")
[1] "10#000" "100" "10#000#000"
#p値の体裁を整える:pコマンド
#棄却域の確率を設定:alphaオプション
#小数点の表示数:digitsオプション
p(x = 0.0001, alpha = .01, digits = 3)
[1] "p < .01"
#試しにxに0.5を設定
p(x = 0.5, alpha = .01, digits = 3)
[1] "p = .500"
###参考:t.testコマンドと組み合わせ#####
ResultTtest <- t.test(1:10, y = c(7:20))
Welch Two Sample t-test
data: 1:10 and c(7:20)
t = -5.4349, df = 21.982, p-value = 1.855e-05
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-11.052802 -4.947198
sample estimates:
mean of x mean of y
5.5 13.5
#検定結果をsprintfコマンドで表示
sprintf(
"t = %s (%s)",
f(ResultTtest$statistic),
p(ResultTtest$p.value, alpha = .000001, digits = 6)
)
[1] "t = -5.435 (p = .000019)"
#参考:formatコマンド
format(c(1:10, "からだにいいもの"))
[1] "1 " "2 " "3 " "4 " "5 " "6 "
[7] "7 " "8 " "9 " "10 " "からだにいいもの"少しでも、あなたのウェブや実験の解析が楽になりますように!!