同じ変数と測定タイミングが異なるデータを1行にまとめるコマンドの紹介です。「tidyr」パッケージを利用すると簡単です。
この紹介は「Rで解析:CSVファイルをまとめて読み込み「readbulk」パッケージ」をご覧になられた方からの質問です。非常にわかりやすい質問で、多くの方の役に立ちそうなので記事にしました。ご質問ありがとうございました。
なお、「readbulk」パッケージはフォルダ内の全CSVを読み込む便利なパッケージです。ただし、1ファイル毎にデータが読み込まれるためファイル数分のNA列が発生します。そんな問題を解決するコマンドの紹介です。
・Rで解析:CSVファイルをまとめて読み込み「readbulk」パッケージ
https://www.karada-good.net/analyticsr/r-338/
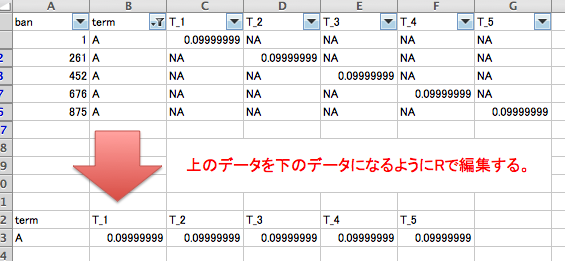
<処理データの例>
実行コマンドはwindows 7およびOS X 10.11.2のR version 3.2.3で確認しています。
実行コマンド
詳細はコメント、各パッケージのヘルプを確認してください。なお、実行コマンドではcsvファイルを読み込み処理した例です。
#CSVファイルを読み込む:read.csvコマンド
library("tcltk")
#日本語を含む場合はfileEncoding="CP932"を追加
#NAの文字列を"NA"値に指定
selectACsv <- paste(as.character(tkgetOpenFile(title = "csvファイルを選択",filetypes = '{"csvファイル" {".csv"}}',initialfile = "*.csv")), sep = "", collapse =" ")
ReadData <- read.csv(selectACsv, header = TRUE, sep = ",", na.strings = "NA", stringsAsFactors = FALSE, fileEncoding = "CP932")
########
#データ確認
ReadData
ban term T_1 T_2 T_3 T_4 T_5
1 1 A 0.099999999 NA NA NA NA
2 261 A NA 0.000999999 NA NA NA
3 452 A NA NA 0.000999999 NA NA
4 676 A NA NA NA 0.000999999 NA
5 875 A NA NA NA NA 0.000999999
###データを整形#####
#tidyrパッケージを利用
library("tidyr")
#パイプ「%>%」ごとの処理内容
#banデータを削除
#「gather」コマンドでtermを基準にデータを縦に並べる
#「spread」コマンドでketに横方向に並べる変数データ列を指定,valueに値列を指定
ResultData <- ReadData[, -1] %>%
gather(key = time, value = Value, -term, na.rm = TRUE) %>%
spread(key = time, value = Value)
#確認
ResultData
term T_1 T_2 T_3 T_4 T_5
1 A 0.09999999 0.09999999 0.09999999 0.09999999 0.09999999少しでも、あなたの解析が楽になりますように!!