データの特徴を把握するのに便利なパッケージの紹介です。基本的な記述統計を簡単に確認することができます。
パッケージバージョンは0.0.2。実行コマンドはwindows 7およびOS X 10.11.5のR version 3.3.0で確認しています。
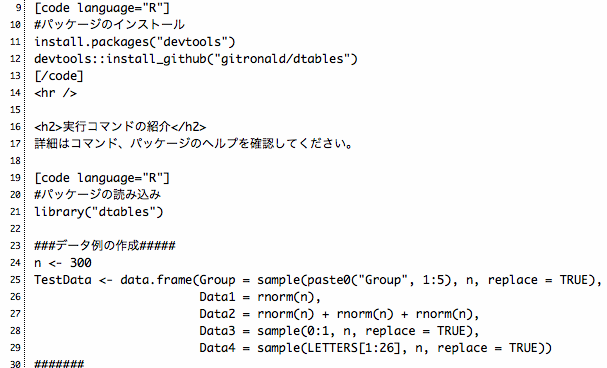
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("devtools")
devtools::install_github("gitronald/dtables")実行コマンド
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("dtables")
###データ例の作成#####
n <- 300
TestData <- data.frame(Group = sample(paste0("Group", 1:5), n, replace = TRUE),
Data1 = rnorm(n),
Data2 = rnorm(n) + rnorm(n) + rnorm(n),
Data3 = sample(0:1, n, replace = TRUE),
Data4 = sample(LETTERS[1:26], n, replace = TRUE))
#######
###データの要約を表示:dftコマンド#####
#割合を表示:propオプション;初期値TRUE
#パーセントを表示:percオプション;初期値TRUE
#基本的な使い方
dft(TestData$Group)
Group n prop perc
1 Group1 62 0.2066667 20.7%
2 Group2 71 0.2366667 23.7%
3 Group3 69 0.2300000 23.0%
4 Group4 51 0.1700000 17.0%
5 Group5 47 0.1566667 15.7%
#byオプションで要素の記述統計が可能です
dft(TestData$Group, by = TestData$Data1)
Group n prop mean sd se
X11 Group1 62 0.21 -0.07 0.94 0.12
X12 Group2 71 0.24 0.00 1.08 0.13
X13 Group3 69 0.23 -0.24 1.01 0.12
X14 Group4 51 0.17 0.29 0.89 0.12
X15 Group5 47 0.16 -0.03 0.97 0.14
#データ構成を表示:dvariableオプション
dvariable(TestData)
variable class mode type levels frequencies statistics
1 Group factor numeric integer 5 1 0
2 Data1 numeric numeric double 300 0 1
3 Data2 numeric numeric double 300 0 1
4 Data3 integer numeric integer 2 1 1
5 Data4 factor numeric integer 26 0 0
#データ要素の記述統計を一括表示:dtableコマンド
dtable(TestData)
Note: 'Data4' was not classified.
$Frequencies
dataset demographic NA. n perc
1 TestData Group Group1 62 20.7%
2 Group2 71 23.7%
3 Group3 69 23.0%
4 Group4 51 17.0%
5 Group5 47 15.7%
6 TestData Data3 0 144 48.0%
7 1 156 52.0%
$Statistics
dataset variable vars n mean sd median trimmed mad min max range skew kurtosis se
X1 TestData Data1 1 300 0.0 1.0 -0.1 0.0 0.9 -2.8 2.9 5.6 0.0 0.2 0.1
X11 TestData Data2 1 300 0.0 1.8 0.0 0.0 1.9 -6.1 4.0 10.1 -0.2 -0.2 0.1
X12 TestData Data3 1 300 0.5 0.5 1.0 0.5 0.0 0.0 1.0 1.0 -0.1 -2.0 0.0
少しでも、あなたの解析が楽になりますように!!