お問い合わせからデータフレームの操作方法について質問をよく受領します。列・行の選択方法、抽出方法や要約・構造の表示方法が多いです。参考までにコマンド例を紹介します。
なお、質問に回答できない場合や問題が解決しないこともありますが、今後も「からだにいいもの」をよろしくお願いします。
なお、Rに収録されている基本的なコマンドを学ぶには下記書籍がおすすめです。
書籍名:Rプログラミングマニュアル(第2版)―Rバージョン3対応
著 者:間瀬 茂
価 格:4,536
発売日:2014/05
出版社:数理工学社
実行コマンドはR version 4.2.2で確認しています。
実行コマンド
詳細はコメント、各パッケージのヘルプを確認してください。
###データ例の作成#####
TestData <- data.frame(Group = sample(paste0("Group", 1:5), 10, replace = TRUE),
Data1 = 1:10,
Data2 = 10:1)
#確認
TestData
Group Data1 Data2
1 Group5 1 10
2 Group4 2 9
3 Group4 3 8
4 Group5 4 7
5 Group4 5 6
6 Group4 6 5
7 Group2 7 4
8 Group5 8 3
9 Group4 9 2
10 Group3 10 1
#######
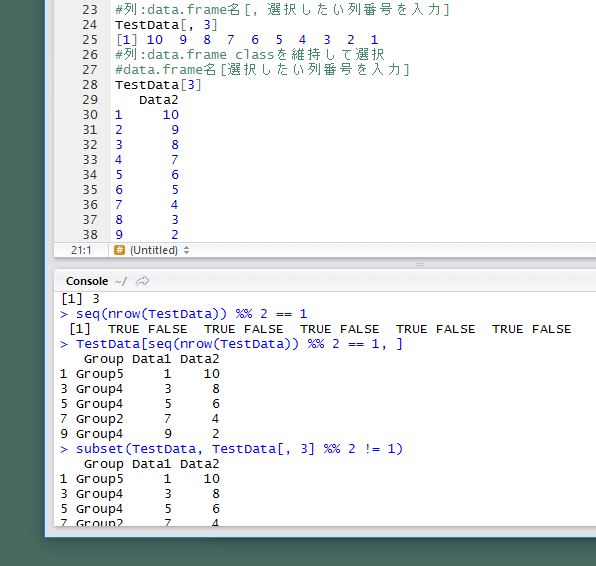
###data.frameから特定の列・行を選択する#####
#列:data.frame名[, 選択したい列番号を入力]
TestData[, 3]
[1] 10 9 8 7 6 5 4 3 2 1
#列:data.frame classを維持して選択
#data.frame名[選択したい列番号を入力]
TestData[3]
Data2
1 10
2 9
3 8
4 7
5 6
6 5
7 4
8 3
9 2
10 1
#行:data.frame名[選択したい列番号を入力, ]
#data.frame classを維持します
TestData[3, ]
Group Data1 Data2
3 Group4 3 8
#################################
###該当する条件のみを抽出する#####
#Data2が偶数を抽出
#例:subsetコマンド
subset(TestData, TestData[, 3] %% 2 == 0)
Group Data1 Data2
1 Group5 1 10
3 Group4 3 8
5 Group4 5 6
7 Group2 7 4
9 Group4 9 2
#否定の比較演算子で再現:!=
subset(TestData, TestData[, 3] %% 2 != 1)
Group Data1 Data2
1 Group5 1 10
3 Group4 3 8
5 Group4 5 6
7 Group2 7 4
9 Group4 9 2
#行番号が奇数を抽出
#例:seq,nrowコマンド
seq(nrow(TestData)) %% 2 == 1, ]
Group Data1 Data2
1 Group5 1 10
3 Group4 3 8
5 Group4 5 6
7 Group2 7 4
9 Group4 9 2
#重複を取り除く
#注意:初めのデータが残ります
#例:duplicatedコマンド
TestData[!duplicated(TestData[, 1]), ]
Group Data1 Data2
1 Group5 1 10
2 Group4 2 9
7 Group2 7 4
10 Group3 10 1
########
###data.frameの要約・構造#####
#要約:summaryコマンド
summary(TestData)
Group Data1 Data2
Group2:1 Min. : 1.00 Min. : 1.00
Group3:1 1st Qu.: 3.25 1st Qu.: 3.25
Group4:5 Median : 5.50 Median : 5.50
Group5:3 Mean : 5.50 Mean : 5.50
3rd Qu.: 7.75 3rd Qu.: 7.75
Max. :10.00 Max. :10.00
#構造:strコマンド
str(TestData)
'data.frame': 10 obs. of 3 variables:
$ Group: Factor w/ 4 levels "Group2","Group3",..: 4 3 3 4 3 3 1 4 3 2
$ Data1: int 1 2 3 4 5 6 7 8 9 10
$ Data2: int 10 9 8 7 6 5 4 3 2 1
########少しでも、あなたの解析が楽になりますように!!