注意:新バージョン登場で本ページの情報は古くなっています。
最新「twitterR」パッケージのバージョン1.1.9の紹介を確認ください。

*2015/06/09 バージョン1.1.8に対応するように記事の内容を更新しました。
*2015/06/20 Rのバージョンが古いと動かないので、対処方法を追記しました。
*2015/07/02 install.packagesコマンドでtwitterRをインストールした時のhttrパッケージを差し替える方法を追記しました。差し替えないとAPI接続に不具合があります。
*2015/07/03 windowsでtar.gzファイルをインストールするのに必要なRtoolsに関する情報を追記しました。
*2015/07/10 httr_0.6.1のzipファイルがダウンロードできるCRANのURLを追記しました。
RはGoogle Analyticsだけでなく、Twitterのタイムラインも取得できます。
そこで、Twitterのタイムラインを取得し、タグクラウドを出力する方法を紹介します。
最近、GoogleでTwitterのリアルタイム検索復活するとニュースも報道されツイート内容の解析に注目が集まっています。個人的にはTwitterは生の声が記録されている媒体と認識しています。
コマンドはR version 3.2.0で確認しています。
もし、動作しないなどがありましたら、お問い合わせからお知らせいただけますと幸いです。
お問い合わせはこちら
https://www.karada-good.net/question/
Twitter APIの取得
Twitterのアカウントを取得していない方は、まずはアカウントを取得してください。
https://twitter.com/

Twitter Developersにアクセスし、赤枠の「Manage Your Apps」をクリックします。
https://dev.twitter.com/

Twitter Appsが表示されます。赤枠の「Create New App」をクリックします。
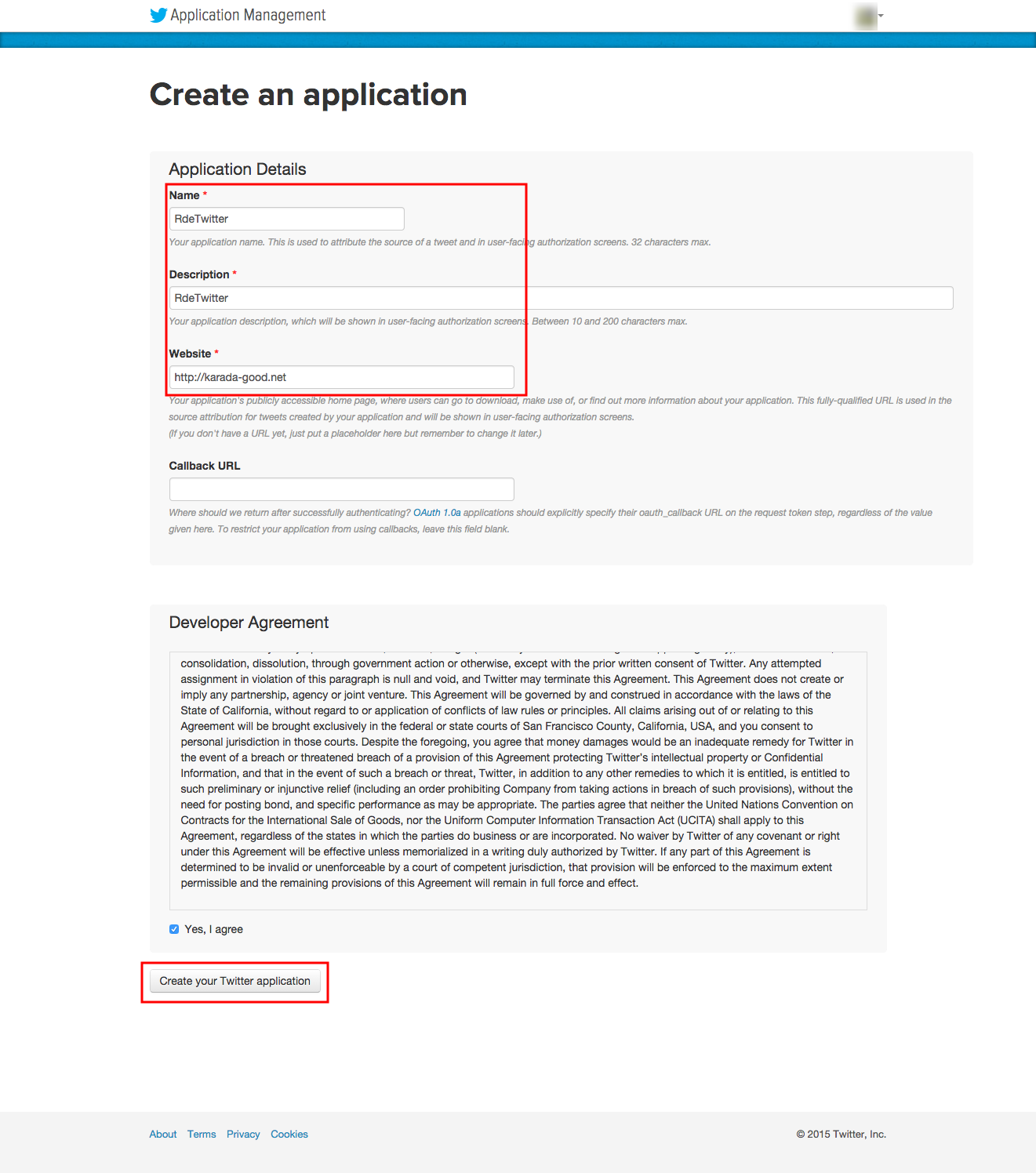
Create an applicationが表示されます。赤枠の項目を入力します。Websiteはhttp://karada-good.netで構いません。入力後、画面最下部青枠「Create your Twitter application」をクリックします。注意:applicationを作成するアカウントに電話番号が登録されていない場合はapplicationを作成するアカウントに電話番号を紐つけするようにしてください。
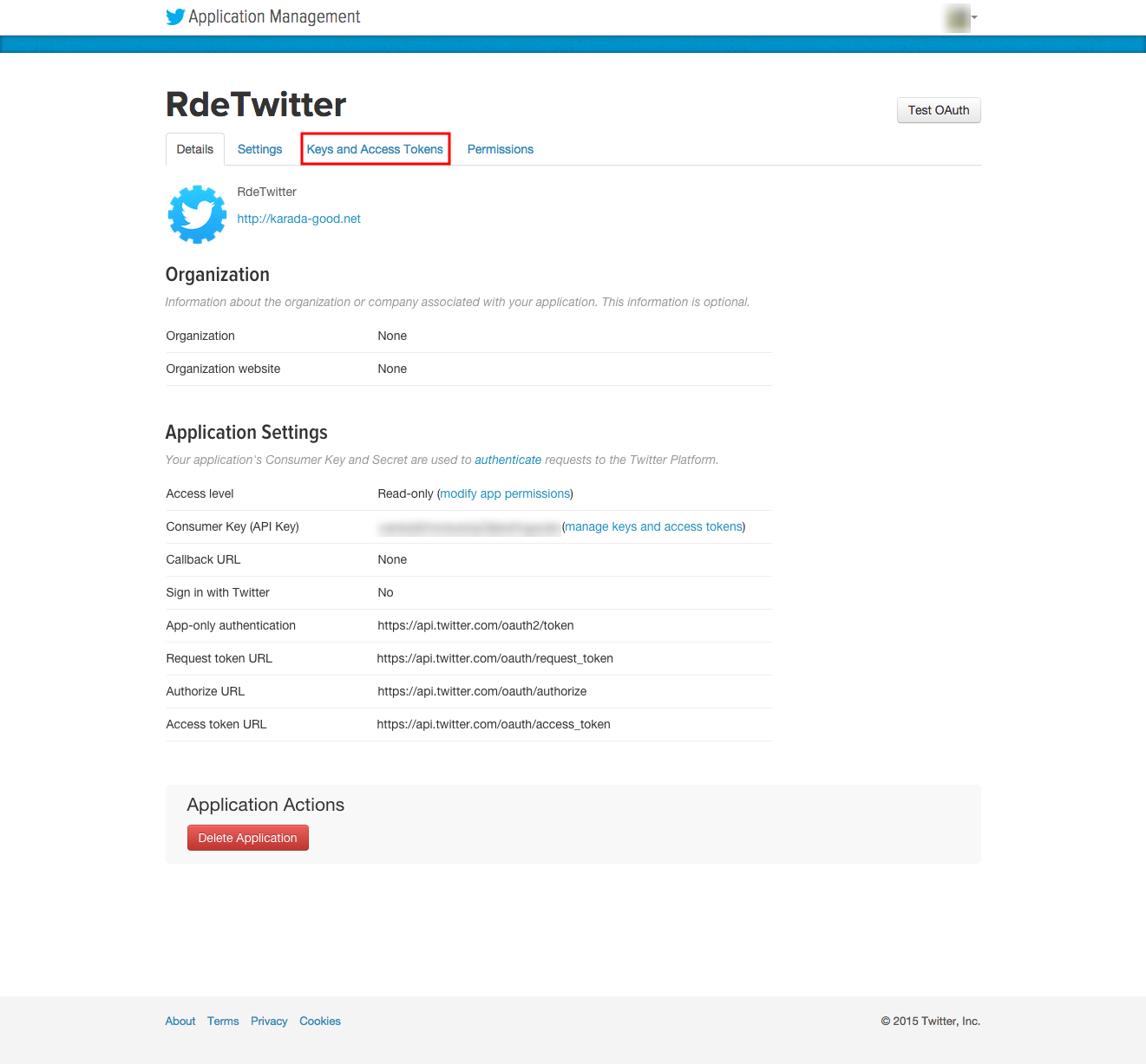
問題がなければRdeTwitterの画面が表示されます。必要な情報を入手するために、赤枠「Keys and Access Tokens」をクリックします。
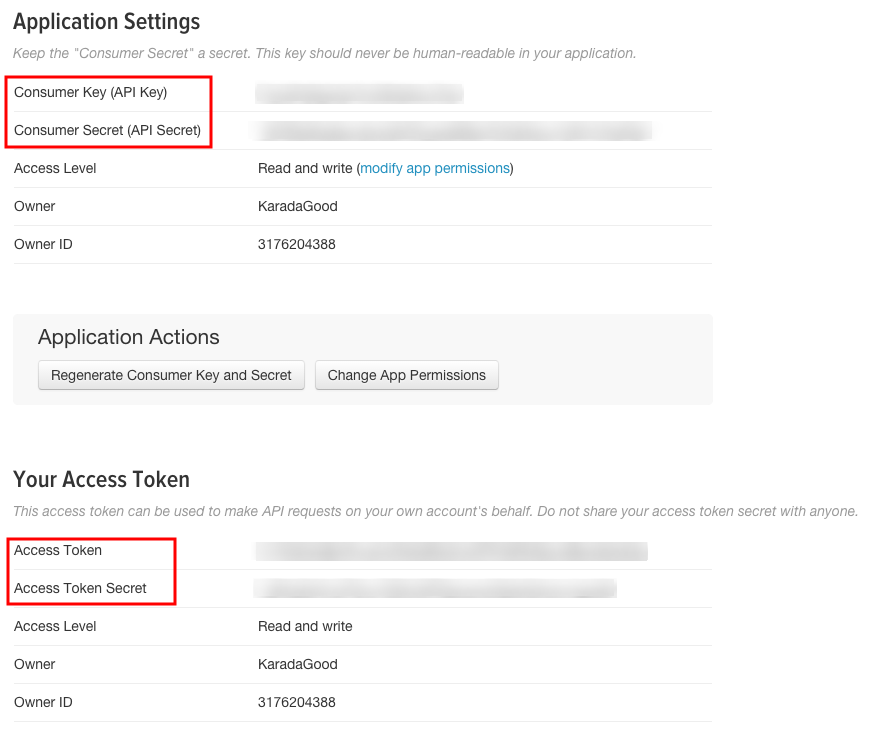
表示される画面、赤枠のConsumer Key (API Key)、Consumer Secret (API Secret)、Access Token、Access Token Secretが解析に必要です。Access Token、Access Token Secretは画面下部にある「Create my access token」をクリックし作成してください。必要な情報はテキストなどにコピーして保存してください。
パッケージのインストール
注意:新バージョン登場で本ページの情報は更新は終了しています。
最新「twitterR」パッケージのバージョン1.1.9の紹介は下記URLの記事を確認ください。インストール方法が簡単になっています。
https://www.karada-good.net/analyticsr/r-170/
<7/30:追記内容 ここから>
twitteR バージョン1.1.8のダウンロードはこちらから
https://cran.r-project.org/bin/windows/contrib/3.0/twitteR_1.1.8.zip
<7/30:追記内容 ここまで>
<7/10:追記内容 ここから>
httr_0.6.1のzipファイルは下記URLからダウンロードできます。tar.gzでうまくいかない方はこちらを利用ください。ページを開き”httr”と検索してください。なお、twitteRのインストール後にhttr_0.6.1のインストールをしてください。
なお、Rのパッケージを使用してダウンロードする方法は下記記事を参考ください。
Rでお遊び:Rからファイルをダウンロードしませんか?「downloader」パッケージの紹介
https://www.karada-good.net/analyticsr/r-143/
http://cran.cnr.berkeley.edu/bin/windows/contrib/3.0/
<7/10:追記内容 ここまで>
<7/02:追記内容 ここから>
httrパッケージのバージョンが0.6.1でないとTwitterよりデータの取得ができないことが分かりました。
twitterRのインストール後に、下記URLより「httr_0.6.1.tar.gz」をダウンロードし、 Rにインストールしてください。
http://cran.r-project.org/src/contrib/Archive/httr/
<7/03:追記内容 ここから>
windowsを利用の方は下記URLより、ご使用のRのバージョンにあったRToolsをダウンロードしてインストールしてください。tar.gzファイルからパッケージをインストールできます。
http://cran.r-project.org/bin/windows/Rtools/
<7/03:ここまで>
library("tcltk")
install.packages(paste(as.character(tkgetOpenFile(title = "パッケージファイルを選択",
filetypes = '{"パッケージファイル" {".*"}}',initialfile = "*.*")),
sep = "", collapse =" "), repos = NULL, type = "source")<7/02:ここまで>
<6/20:追記内容 ここから>
Rのバージョンが古いと正しく動かないようです。できるだけ最新のRをご利用いただければ。また、twitteRパッケージではDBI (>= 0.3.1), httr (>= 0.6.0)が求められます。ご注意を。
なお、紹介コードは次の環境で動作を確認しています:R version 3.2.0 (2015-04-16) twitteR Version: 1.1.8 OS:windows 7 64 bit / MAC OS 10.10.3(14D136)
念のためRの説明記事を紹介
Rのガイド:研究者も、社会人も、おねえさんも。とりあえず、みんなで使ってみませんか?
https://www.karada-good.net/analyticsr/r-90/
<ここまで>
Twitterとの連携
コマンドを実行すると連携が完了します。twitter APIはデータ取得に制限があります。詳細は下記のリンクを参照ください。
公式:Twitterリミット (API、ツイート投稿、およびフォロー)
https://support.twitter.com/articles/249071-twitter-apidm
#ライブラリの読み込み
library("twitteR")
#情報の入力
consumerKey <- "Consumer Key (API Key)を入力"
consumerSecret <- "Consumer Secret (API Secret)を入力"
accessToken <- "Access Tokenを入力"
accessSecret <- "Access Token Secretを入力"
#処理の準備
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
2015/07/02 入力例の画像を追加しました。情報はクォーテーションマーク(” “)で囲って入力します。
実行すると、[1] “Using direct authentication”と表示されます。これで、データの取得準備は完了です。
Twitterから情報を取得する
キーワードで検索しデータフレームで出力します。画像エクセルが出力されます。
#検索キーワードの設定
SearchWords <- c("karada-good.net")
#検索
TwGetDF <- twListToDF(searchTwitter(SearchWords, n = 20))
#保存フォルダを選択して書き出し。
library("tcltk")
#install.packages("XLConnect") #XLConnectがインストールされていない場合は実行
library("XLConnect")
setwd(paste(as.character(tkchooseDirectory(title = "保存ディレクトリを選択"), sep = "", collapse ="")))
writeWorksheetToFile(paste("TwitterData.xlsx", sep = ""), data = TwGetDF, sheet = "TwitterData")
########
キーワード”karada-good.net”で検索して出力されたエクセルです。
トレンドワードTop10の取得。地域はwoeidで指定します。例は日本のトレンドワードを取得するコマンドです。
#地域idは下記コマンドで取得
#availableTrendLocations()
TrendWords <- data.frame(TrendWord = getTrends(woeid = 23424856)$name)
TrendWords
TrendWord
1 #あなたは何なのか
2 #これを見た人は黄色の画像を貼れ
3 ジャパン
4 #r_housoku
5 得意属性
6 音ゲーアプリ診断
7 梅雨入り
8 HAKUEI
9 チルノ
10 ペヤング
#保存フォルダを選択して書き出し。
library("tcltk")
#install.packages("XLConnect") #XLConnectがインストールされていない場合は実行
library("XLConnect")
setwd(paste(as.character(tkchooseDirectory(title = "保存ディレクトリを選択"), sep = "", collapse ="")))
writeWorksheetToFile(paste("TrendWordsData.xlsx", sep = ""), data = TrendWords, sheet = "TrendWordsData")
########参考、日本のwoeid一覧です。
woeid <- availableTrendLocations() subset(woeid, country == "Japan") name country woeid 192 Kitakyushu Japan 1110809 193 Saitama Japan 1116753 194 Chiba Japan 1117034 195 Fukuoka Japan 1117099 196 Hamamatsu Japan 1117155 197 Hiroshima Japan 1117227 198 Kawasaki Japan 1117502 199 Kobe Japan 1117545 200 Kumamoto Japan 1117605 201 Nagoya Japan 1117817 202 Niigata Japan 1117881 203 Sagamihara Japan 1118072 204 Sapporo Japan 1118108 205 Sendai Japan 1118129 206 Takamatsu Japan 1118285 207 Tokyo Japan 1118370 208 Yokohama Japan 1118550 333 Okinawa Japan 2345896 399 Osaka Japan 15015370 400 Kyoto Japan 15015372 428 Japan Japan 23424856 467 Okayama Japan 90036018
参考:キーワードで検索したツイートの結果をワードクラウドで出力する。
なぜか、twitterRの記事を編集すると地震が起きます。2015/6/9 5:50にキーワード「地震」で検索したツイートの結果をワードクラウドで出力してみました。
なお、データのクリーニングはしていません。
RMeCabのインストール方法はこちらから。ぜひ、参照してタグクラウドを作成してください。
Rでウェブ解析:テキストマイニングとタグクラウド
library("RMeCab")
library("wordcloud")
SearchWords <- c("地震")
TwGetDF <- twListToDF(searchTwitter(searchString = SearchWords, #検索キーワード
n = 100 #取得するツイート数))
###単語の出現数設定。20以上での抽出結果となります。出現数は適時調整してください。#####
WordFreq <- 20
########
###単語解析######
res <- docMatrixDF(TwGetDF[, 1], pos = c("名詞", "形容詞", "動詞"))
res <- res[row.names(res) != "[[LESS-THAN-1]]", ] #[[LESS-THAN-1]]の削除
resc <- res[row.names(res) != "[[TOTAL-TOKENS]]", ] #[[TOTAL-TOKENS]]の削除
########
###単語解析結果をデータフレーム化#####
AnalyticsFileDoc <- as.data.frame(apply(resc, 1, sum)) #単語の出現数を集計
AnalyticsFileDoc <- subset(AnalyticsFileDoc, AnalyticsFileDoc[, 1] >= WordFreq) #出現数で抽出
colnames(AnalyticsFileDoc) <- "出現数" #行名の設定
########
###タグクラウドのテキストの色を設定#####
Col <- c("#deb7a0", "#505457", "#4b61ba") #文字色の指定
########
###タグクラウドのプロット#####
#par(family = "HiraKakuProN-W3") #実行でMACの文字化け防止
wordcloud(row.names(AnalyticsFileDoc), AnalyticsFileDoc[, 1], scale = c(6, .2),
random.order = T, rot.per = .15, colors = Col)
########出力結果

少しでも、あなたのウェブや実験の解析が楽になりますように!!