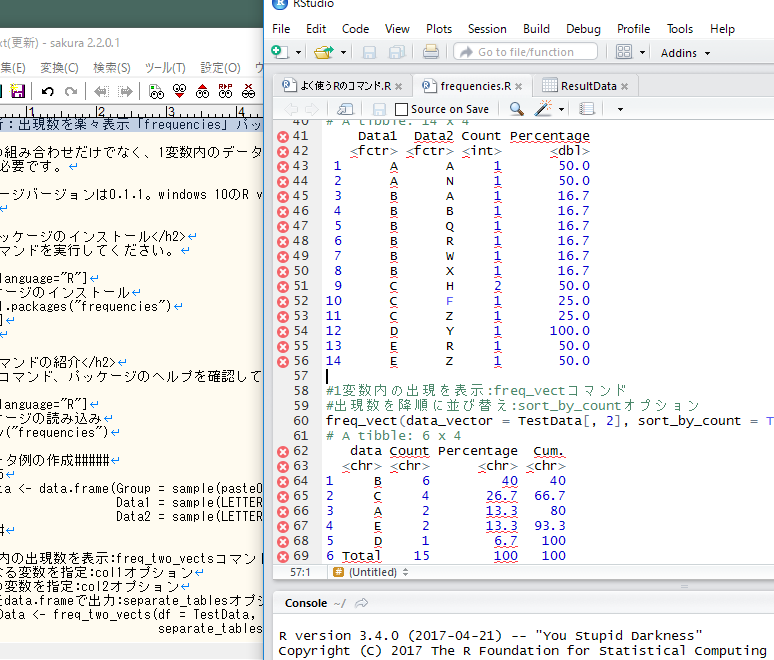
2変数の組み合わせだけでなく、1変数内のデータの出現数を計算してくれるパッケージの紹介です。なお、利用にはR version 3.4.0以上が必要です。
パッケージバージョンは0.1.1。windows 10のR version 3.4.0で動作を確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("frequencies")コマンドの紹介
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("frequencies")
###データ例の作成#####
n <- 15
TestData <- data.frame(Group = sample(paste0("Group", 1:5), n, replace = TRUE),
Data1 = sample(LETTERS[1:5], n, replace = TRUE),
Data2 = sample(LETTERS[1:26], n, replace = TRUE))
#######
#2変数内の出現数を表示:freq_two_vectsコマンド
#主となる変数を指定:col1オプション
#対象の変数を指定:col2オプション
#結果をdata.frameで出力:separate_tablesオプション
ResultData <- freq_two_vects(df = TestData, col1 = Data1, col2 = Data2,
separate_tables = FALSE)
#確認
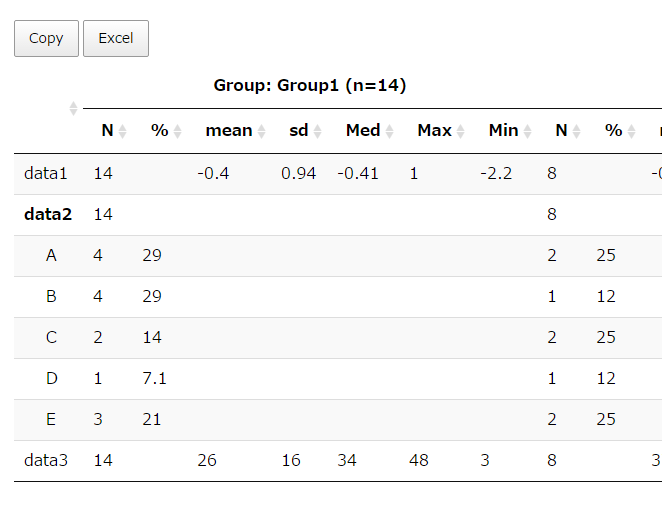
ResultData
# A tibble: 55 x 4
Data1 Data2 Count Percentage
1 A A 1 50
2 A N 1 50
3 A B 0 0
4 A F 0 0
5 A H 0 0
6 A Q 0 0
7 A R 0 0
8 A W 0 0
9 A X 0 0
10 A Y 0 0
# ... with 45 more rows
#出現数が1以上を抽出
subset(ResultData, ResultData[, 3] > 0)
# A tibble: 14 x 4
Data1 Data2 Count Percentage
1 A A 1 50.0
2 A N 1 50.0
3 B A 1 16.7
4 B B 1 16.7
5 B Q 1 16.7
6 B R 1 16.7
7 B W 1 16.7
8 B X 1 16.7
9 C H 2 50.0
10 C F 1 25.0
11 C Z 1 25.0
12 D Y 1 100.0
13 E R 1 50.0
14 E Z 1 50.0
#1変数内の出現を表示:freq_vectコマンド
#出現数を降順に並び替え:sort_by_countオプション
freq_vect(data_vector = TestData[, 2], sort_by_count = TRUE, total_row = TRUE)
# A tibble: 6 x 4
data Count Percentage Cum.
1 B 6 40 40
2 C 4 26.7 66.7
3 A 2 13.3 80
4 E 2 13.3 93.3
5 D 1 6.7 100
6 Total 15 100 100少しでも、あなたの解析が楽になりますように!!