数字の桁揃えや小数点の切り上げ・切り捨てなどの書式設定だけでなく、テキストの置換を条件で設定可能な大変便利なコマンドが収録されているパッケージの紹介です。データフレームの列データを指定書式で結合する「fapply2」コマンドは「tidyverse」パッケージと組み合わせて使用すると大変便利だと思います。
パッケージバージョンは1.6.5。windows11のR version 4.3.3で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
# パッケージのインストール
install.packages("fmtr")実行コマンド
「実行準備」、「ベクトルの書式を整える」、「データフレームの書式を整える」、「再利用可能な書式形式を作成」の順にコマンドを紹介します。詳細はコメント、コマンドヘルプを確認してください。
実行準備
# パッケージの読み込み
library("fmtr")
### データ例の準備 #####
# tidyverseパッケージを読み込み
# tidyverseパッケージがなければインストール
if(!require("tidyverse", quietly = TRUE)){
install.packages("tidyverse");require("tidyverse")
}
# 乱数の固定
set.seed(1980)
# データ例の作成
n <- 10
TestData <- tibble(Group = sample(paste0("Group", 1:5),
n, replace = TRUE),
Data1 = rnorm(n),
Data2 = sample(900:1500,
n, replace = TRUE))
# 確認
TestData
# A tibble: 10 × 3
Group Data1 Data2
<chr> <dbl> <int>
1 Group2 2.03 1162
2 Group1 0.475 1451
3 Group2 -0.933 1293
4 Group3 1.89 1367
5 Group4 0.952 956
6 Group4 -1.67 1258
7 Group1 0.449 1453
8 Group4 0.0517 1475
9 Group5 -0.280 1406
10 Group2 0.0243 918
########ベクトルの書式を整える
指定した少数の位置で四捨五入、%の付与、指定した文字長、文字列の右寄せ・左寄せ・幅揃えなどが「fapply」コマンドで可能です。また、収録されている「value」コマンドと「condition」コマンドと「fapply」コマンドを組み合わせると、文字や数字を指定書式で置換可能です。
また、「function」コマンドをベクトルに適応する「vectorize」コマンドは大変便利だと思います。内部では「lapply」コマンドと「mapply」コマンドで対処しているようです。
# ベクトルの書式を整える:fapplyコマンド
# 書式を指定:formatオプション
# 文字列の幅を指定:widthオプション
# 文字寄せを指定:justifyオプション;"left","right","center","centre","none"
# 指定した少数点桁で四捨五入:"%.(少数点桁数)f"
## 例_小数第二位で四捨五入
fapply(TestData$Data1, format = "%.2f")
[1] "2.03" "0.48" "-0.93" "1.89" "0.95" "-1.67" "0.45" "0.05" "-0.28" "0.02"
## 例_小数第一位で四捨五入して%を末尾に付与:"%.(少数点桁数)f"
fapply(TestData$Data1, format = "%.1f%%")
[1] "2.0%" "0.5%" "-0.9%" "1.9%" "1.0%" "-1.7%" "0.4%" "0.1%" "-0.3%" "0.0%"
## 例_小数第一位で四捨五入して文字長を6で右寄せ:format,width,justifyオプションを適用
fapply(TestData$Data1, format = "%.1f", width = 6, justify = "right")
[1] " 2.0" " 0.5" " -0.9" " 1.9" " 1.0" " -1.7" " 0.4" " 0.1" " -0.3" " 0.0"
## 例_formatにfunctionを設定し桁区切りを適用:function(x) format(x, big.mark = ",")
fapply(TestData$Data2, format = function(x) format(x, big.mark = ","))
[1] "1,162" "1,451" "1,293" "1,367" " 956" "1,258" "1,453" "1,475" "1,406" " 918"
## テキストの置換:fmtr::value,fmtr::conditionを組み合わせる
## 例_fmtr::conditionno条件を文字列で指定し置換
ChangeText <- value(condition(x == "Group1", "G1"),
condition(x == "Group2" | x == "Group3", "G6"),
condition(x == "Group4" | x == "Group5", "G7"))
fapply(TestData$Group, format = ChangeText)
[1] "G6" "G1" "G6" "G6" "G7" "G7" "G1" "G7" "G7" "G6"
## 例_fmtr::conditionno条件を数字で指定し置換
ChangeValue <- value(condition(x <= -0.3, "LOW"),
condition(x > -0.3 | x <= 0.5, "Middle"),
condition(x > 0.5, "High"))
fapply(TestData$Data1, format = ChangeValue)
[1] "Middle" "Middle" "LOW" "Middle" "Middle" "LOW" "Middle" "Middle" "Middle" "Middle"
########
## 「function」コマンドをベクトルに適応する:Vectorizeコマンド
# テストデータ
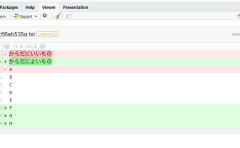
Test <- c("karada", NA, "Good", "からだに", "いいもの")
# Vectorizeコマンドでfunctionコマンドを適応する
# NAをありゃ,からだとkaradaをLabel からだ/karada,その他をいいものに置換
AppFunction <- Vectorize(function(x) {
if (is.na(x))
ret <- "ありゃ"
else if (x %in% c("からだに", "karada"))
ret <- paste("Label", x)
else
ret <- "いいもの"
return(ret)
})
# fapplyコマンドで適応
fapply(Test, AppFunction)
[1] "Label karada" "ありゃ" "いいもの" "Label からだに" "いいもの"
########データフレームの書式(桁区切りや小数点)を整える
「format」コマンドでデータを指定し、「value」コマンドと「condition」コマンドで書式などを指定します。複数書式は紹介のようにlist形式で設定すると楽です。
列データを指定書式で結合する「fapply2」コマンドは「dplyr::mutate」コマンドを組み合わせて使用すると大変便利だと思います。
# list形式など書式を設定:formatsコマンド
# 例_Data2に桁区切りを適用
formats(TestData) <- list(Group = value(condition(x == "Group1", "G1"),
condition(x == "Group2" | x == "Group3", "G6"),
condition(x == "Group4" | x == "Group5", "G7")),
Data1 = value(condition(x <= -0.3, "LOW"),
condition(x > -0.3 | x <= 0.5, "Middle"),
condition(x > 0.5, "High")),
Data2 = function(x) format(x, big.mark = ","))
# formatsコマンドをデータへ適応:fdataコマンド
fdata(TestData)
# A tibble: 10 × 3
Group Data1 Data2
<chr> <chr> <chr>
1 G6 Middle "1,162"
2 G1 Middle "1,451"
3 G6 LOW "1,293"
4 G6 Middle "1,367"
5 G7 Middle " 956"
6 G7 LOW "1,258"
7 G1 Middle "1,453"
8 G7 Middle "1,475"
9 G7 Middle "1,406"
10 G6 Middle " 918"
# 列データを指定書式で結合する:fapply2コマンド
# 列データを指定:x1,x2オプション
# 書式を指定:format1:x1データ書式,format2:x2データ書式
# dplyr::mutateコマンドを組み合わせると便利です
TestData |>
mutate(NewData = fapply2(x1 = Group,
format1 = value(condition(x == "Group1", "G1"),
condition(x == "Group2" | x == "Group3", "G6"),
condition(x == "Group4" | x == "Group5", "G7")),
x2 = Data2,
format2 = function(x) format(x, big.mark = ","),
sep = "_"))
# A tibble: 10 × 4
# Group Data1 Data2 NewData
# <chr> <dbl> <int> <chr>
# 1 Group2 2.03 1162 G6_1,162
# 2 Group1 0.475 1451 G1_1,451
# 3 Group2 -0.933 1293 G6_1,293
# 4 Group3 1.89 1367 G6_1,367
# 5 Group4 0.952 956 G7_ 956
# 6 Group4 -1.67 1258 G7_1,258
# 7 Group1 0.449 1453 G1_1,453
# 8 Group4 0.0517 1475 G7_1,475
# 9 Group5 -0.280 1406 G7_1,406
# 10 Group2 0.0243 918 G6_ 918データフレームの情報をまとめるのに便利なコマンド
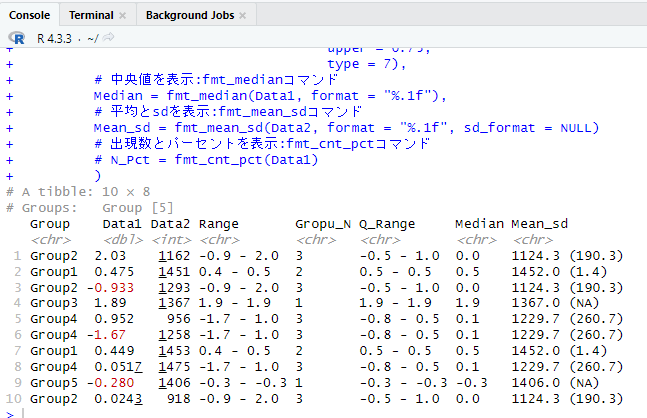
データ範囲、N数、四分位範囲、中央値、平均とsd、出現数とパーセントを表示するのに便利なコマンドの紹介です。「dplyr::mutate」コマンドを組み合わせて使用すると大変便利だと思います。
TestData |>
group_by(Group) |>
mutate(# データ範囲を表示:fmt_rangeコマンド
Range = fmt_range(Data1, format = "%.1f", sep = "-"),
# N数を表示:fmt_nコマンド
Gropu_N = fmt_n(Data1),
# 四分位範囲を表示:fmt_quantile_rangeコマンド
Q_Range = fmt_quantile_range(Data1, format = "%.1f",
sep = "-",
lower = 0.25,
upper = 0.75,
type = 7),
# 中央値を表示:fmt_medianコマンド
Median = fmt_median(Data1, format = "%.1f"),
# 平均とsdを表示:fmt_mean_sdコマンド
Mean_sd = fmt_mean_sd(Data2, format = "%.1f", sd_format = NULL)
# 出現数とパーセントを表示:fmt_cnt_pctコマンド
# N_Pct = fmt_cnt_pct(Data1)
)
# A tibble: 10 × 8
# Groups: Group [5]
# Group Data1 Data2 Range Gropu_N Q_Range Median Mean_sd
# <chr> <dbl> <int> <chr> <chr> <chr> <chr> <chr>
# 1 Group2 2.03 1162 -0.9 - 2.0 3 -0.5 - 1.0 0.0 1124.3 (190.3)
# 2 Group1 0.475 1451 0.4 - 0.5 2 0.5 - 0.5 0.5 1452.0 (1.4)
# 3 Group2 -0.933 1293 -0.9 - 2.0 3 -0.5 - 1.0 0.0 1124.3 (190.3)
# 4 Group3 1.89 1367 1.9 - 1.9 1 1.9 - 1.9 1.9 1367.0 (NA)
# 5 Group4 0.952 956 -1.7 - 1.0 3 -0.8 - 0.5 0.1 1229.7 (260.7)
# 6 Group4 -1.67 1258 -1.7 - 1.0 3 -0.8 - 0.5 0.1 1229.7 (260.7)
# 7 Group1 0.449 1453 0.4 - 0.5 2 0.5 - 0.5 0.5 1452.0 (1.4)
# 8 Group4 0.0517 1475 -1.7 - 1.0 3 -0.8 - 0.5 0.1 1229.7 (260.7)
# 9 Group5 -0.280 1406 -0.3 - -0.3 1 -0.3 - -0.3 -0.3 1406.0 (NA)
# 10 Group2 0.0243 918 -0.9 - 2.0 3 -0.5 - 1.0 0.0 1124.3 (190.3)再利用可能なフォーマット形式を作成
# fcatコマンド
TestFormats <- fcat(Group = value(condition(x == "G1", "Group1"),
condition(x == "G6", "Group2"),
condition(x == "G7", "Group3")),
Data1 = value(condition(x <= -0.3, "LOW"),
condition(x > -0.3 | x <= 0.5, "Middle"),
condition(x > 0.5, "High")),
Data2 = function(x) format(x, big.mark = ","))
# 例1
fapply(c("G7", "G6", "G6", "G1", "G1", "G7", "G6", "G6", "G7", "G7"),
TestFormats$Group)
[1] "Group3" "Group2" "Group2" "Group1" "Group1" "Group3" "Group2" "Group2" "Group3" "Group3"
# 例2
fapply(c(-0.67, 0.67), TestFormats$Data1)
[1] "LOW" "Middle"
# 例3
formats(TestData) <- TestFormats
fdata(TestData)
# A tibble: 10 × 3
Group Data1 Data2
<chr> <chr> <chr>
1 Group2 Middle "1,162"
2 Group1 Middle "1,451"
3 Group2 LOW "1,293"
4 Group3 Middle "1,367"
5 Group4 Middle " 956"
6 Group4 LOW "1,258"
7 Group1 Middle "1,453"
8 Group4 Middle "1,475"
9 Group5 Middle "1,406"
10 Group2 Middle " 918"
# フォーマット形式を作業フォルダに保存:write.fcatコマンド
write.fcat(TestFormats)
# フォーマット形式を読み込み:read.fcatコマンド
# ファイルパスを指定:file_pathオプション
read.fcat(file_path)データの書式設定例の紹介

少しでも、あなたの解析が楽になりますように!!