正確に数値を把握することはできませんが、タグクラウドとも呼ばれるワードクラウドは「文字でデータの特徴」を感覚に強く訴える表現方法だと思います。最近では検索キーワード、twitter内容などのテキストマイニングの分野だけでなく、遺伝子やメタボロームなどのオミクス解析でも見かけるようになりました。
そこで、ワードクラウドが手軽に作成できる「wordcloud」パッケージを紹介します。
パッケージバージョンは2.6。実行コマンドはR version 4.1.2で確認しています。
パッケージのインストール
wordcloudパッケージをインストールすると同時に色の設定・カラーパレット作成可能な「RColorBrewer」パッケージがインストールされます。
#パッケージのインストール
install.packages("wordcloud")コマンド一覧
wordcloudパッケージで使用できるコマンド一覧です。各コマンドのオプションにはplotコマンドのオプション「xlab」や「ylb」などが使用できます。
| タイプ | 内容 | コマンドとオプション | 補足 |
|---|---|---|---|
| プロット | グループ間で共通して出現する単語を、グループ間で出現頻度の差が小さい順番に表示します。 | commonality.cloud(term.matrix, max.words = 300) | max.words:データから表示する単語数を設定します。 |
| プロット | あるグループのみに出現する単語を最優先に、グループ毎の出現数が多くかつグループ間の出現頻度の差が小さい順に単語をグループカラーで表示します。 | comparison.cloud(term.matrix, scale = c(4,.5), max.words=300, random.order = FALSE, rot.per = .1, colors = brewer.pal(ncol(term.matrix), "Dark2"), use.r.layout = FALSE, title.size = 3) | 2グループの比較はデータがプロットされますが、色の設定についてメッセージが表示されます。気になる方はcolorsの設定を指定してください。例:c("red", "blue") |
| データ | 労働組合のスピーチ内容です。 | data(SOTU) | リスト形式です。 |
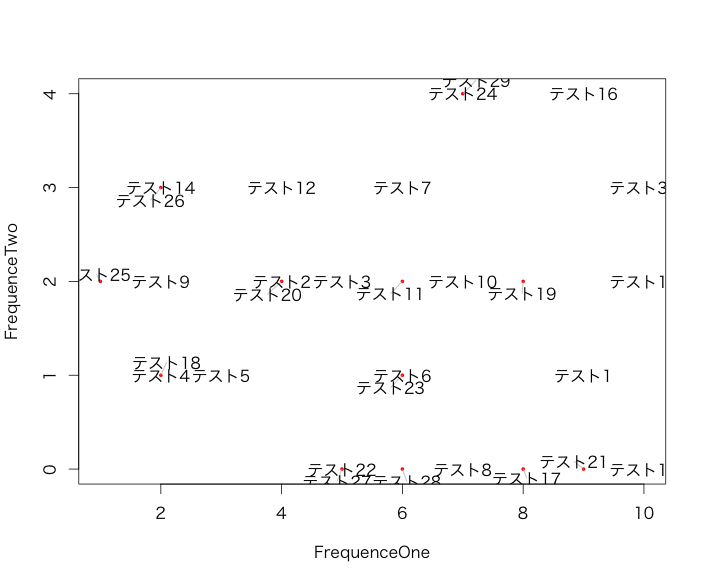
| プロット | 重なりがなく、X軸とY軸の座標データにテキストをプロットします。 | textplot(x, y, words, cex = 1, new = TRUE, show.lines = TRUE) | |
| プロット | ワードクラウドをプロットします。 | wordcloud(words, freq, scale = c(4,.5), min.freq = 3, max.words = Inf, random.order = TRUE, random.color = FALSE, rot.per = .1, colors = "black", ordered.colors = FALSE, use.r.layout = FALSE, fixed.asp = TRUE) | scale:配列で指定します。c(文字の大きさ, 文字間)です。 random.order:FALSEの場合、出現数が高い順からプロットします。 min.freq:プロットする単語の最低出現数です。 random.color:FALSEの場合、出現数が高い順に色を指定します。 order.colors:TRUEの場合、単語の並び順に色を指定します。 |
| 計算 | データから重なりがないように、テキストのプロット座標を計算してマトリックスで出力します。 | wordlayout(x, y, words, cex = 1, rotate90 = FALSE, xlim = c(-Inf,Inf), ylim = c(-Inf,Inf), tstep = .1, rstep = .1) | 結果は引数に代入することができます。 |
コマンドの実行例
詳細はコマンド内の詳細を確認ください。
#ライブラリの読み込み
library("wordcloud")
#macで日本語文字化け防止は下記を実行
#par(family = "HiraKakuProN-W3")
#データ例を作成
TestData <- data.frame(FrequenceOne = sample(1:10, 30, replace = TRUE),
FrequenceTwo = sample(0:4, 30, replace = TRUE),
row.names = paste("テスト", 1:30, sep = ""))
#commonality.cloudコマンド
commonality.cloud(TestData, max.words = 10, random.order = FALSE)
#comparison.cloudコマンド
comparison.cloud(TestData, max.words = 9, colors = c("red", "green"), random.order = FALSE)
#textplotコマンド
textplot(TestData[,1], TestData[,2], rownames(TestData),
xlab = "FrequenceOne", ylab = "FrequenceTwo")
#wordcloudコマンド
wordcloud(rownames(TestData), TestData[,1], scale = c(3, .5),
random.order = FALSE, rot.per = .1, random.color = TRUE, colors = brewer.pal(8, "Dark2"))
#wordlayoutコマンド
wordlayout(TestData[,1], TestData[,2], rownames(TestData))出力例
commonality.cloudコマンド
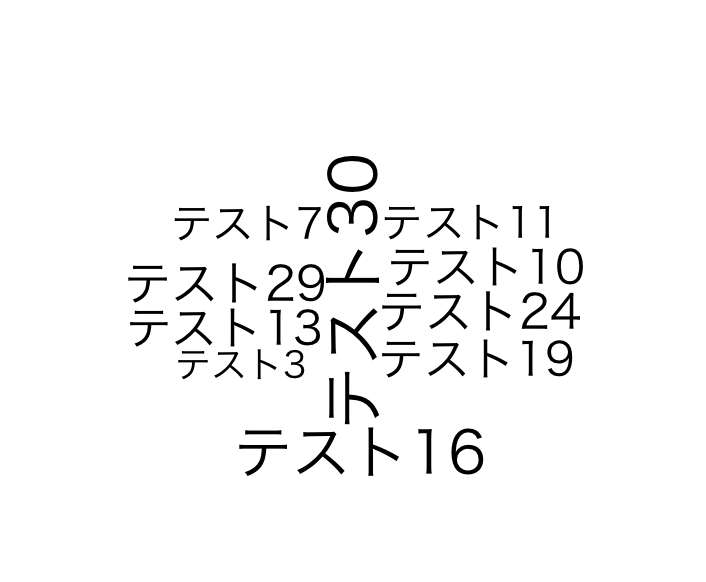
comparison.cloudコマンド
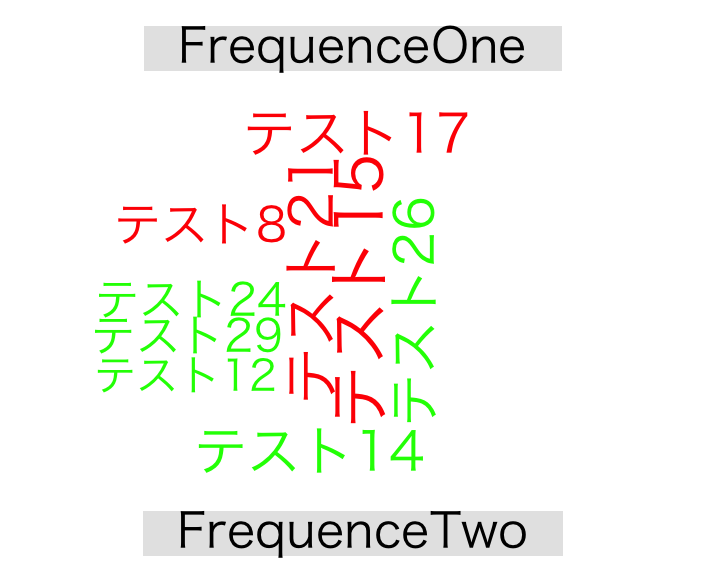
textplotコマンド
wordcloudコマンド
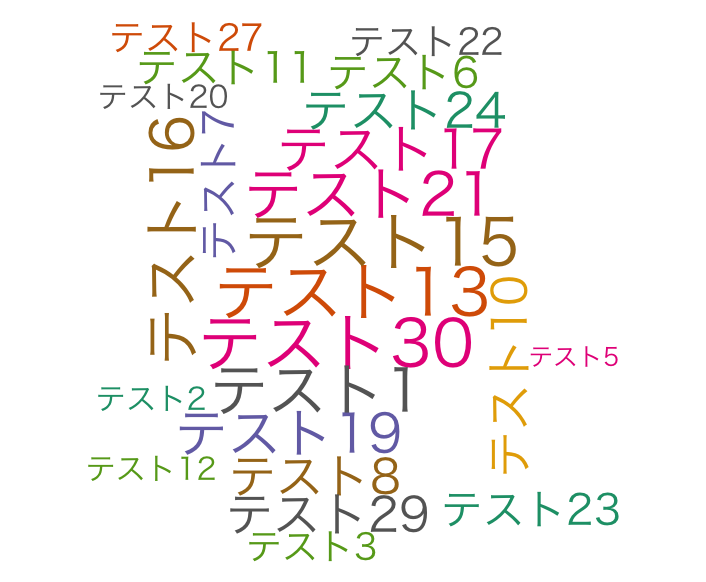
少しでも、あなたの解析が楽になりますように!!