本パッケージは「dplyrパッケージ」と「tidyrパッケージ」の各処理コマンドの要約をコンソールに表示するパッケージの紹介です。例えば、ある処理コマンドを作成してから時間が経過すると、各処理コマンドを何故使用したかを忘れがちです。そんな時に、本パッケージ実行後に処理コマンドを実行すると、各処理コマンドの要約をコンソールに表示してくれますので、記憶の確認に便利だと思います。
なお、本パッケージは「dplyrパッケージとtidyrパッケージのコマンドのラッパー関数」が収録されています。対象としている「dplyrパッケージとtidyrパッケージのコマンド」は下記内容です。
| add_count | mutate | separate_wider_position | transmute_all |
| add_tally | mutate_all | separate_wider_regex | transmute_at |
| anti_join | mutate_at | slice | transmute_if |
| count | mutate_if | slice_head | uncount |
| distinct | pivot_longer | slice_max | ungroup |
| distinct_all | pivot_wider | slice_min | |
| distinct_at | relocate | slice_sample | |
| distinct_if | rename | slice_tail | |
| drop_na | rename_all | spread | |
| fill | rename_at | summarise | |
| filter | rename_if | summarise_all | |
| filter_all | rename_with | summarise_at | |
| filter_at | replace_na | summarise_if | |
| filter_if | right_join | summarize | |
| full_join | sample_frac | summarize_all | |
| gather | sample_n | summarize_at | |
| group_by | select | summarize_if | |
| group_by_all | select_all | tally | |
| group_by_at | select_at | tidylog | |
| group_by_if | select_if | top_frac | |
| inner_join | semi_join | top_n | |
| left_join | separate_wider_delim | transmute |
パッケージバージョンは1.1.0。実行コマンドはwindows 11のR version 4.3.3で確認しています。
パッケージのインストール
下記コマンドを実行してください。
# パッケージのインストール
install.packages("tidylog")コマンドの紹介
詳細はコマンド、パッケージのヘルプを確認してください。
# パッケージの読み込み
library("tidylog")
### 準備 #####
## tidyverseパッケージの読み込み
# tidyverseパッケージがなければインストール
if(!require("tidyverse", quietly = TRUE)){
install.packages("tidyverse");require("tidyverse")
}
## データ例の作成
set.seed(1234)
Test_Data <- data.frame(Chr = sample(LETTERS[c(1, 5, 8)],
size = 100,
replace = TRUE),
Group = sample(LETTERS[1:3],
size = 100,
replace = TRUE),
Number = sample(1:100,
size = 100,
replace = TRUE))
##
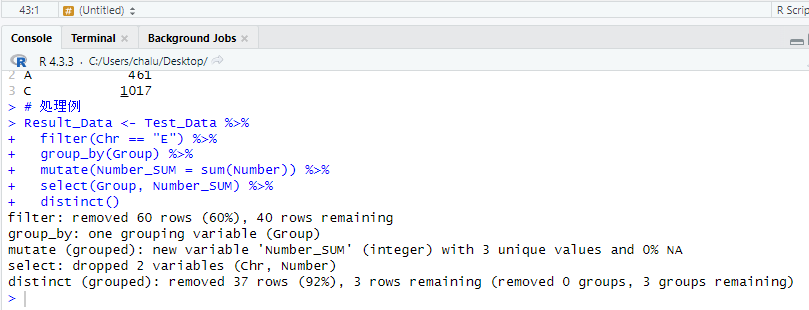
# 処理例
Result_Data <- Test_Data %>%
filter(Chr == "E") %>%
group_by(Group) %>%
mutate(Number_SUM = sum(Number)) %>%
select(Group, Number_SUM) %>%
distinct()
### 以下,コンソールでの表示 #####
filter: removed 60 rows (60%), 40 rows remaining
group_by: one grouping variable (Group)
mutate (grouped): new variable 'Number_SUM' (integer) with 3 unique values and 0% NA
select: dropped 2 variables (Chr, Number)
distinct (grouped): removed 37 rows (92%), 3 rows remaining (removed 0 groups, 3 groups remaining)
########少しでも、あなたの解析が楽になりますように!!