同じ文字列の出現順に番号を付けて一意にするパッケージの紹介です。文字列を処理する場合に便利なパッケージだと思います。
パッケージバージョンは1.0.0。実行コマンドはwindows 11のR version 4.4.1で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
# パッケージのインストール
install.packages("makeunique")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
# パッケージの読み込み
library("makeunique")
### データ例の作成 #####
# 乱数の設定
set.seed(1234)
n <- 20
# 作成
TestData <- sample(c("KARAD", "からだに", "いいもの", "GOOD",
"同じ文字列", "出現順に番号を付ける", "$", "~"), n, replace = TRUE)
# 確認
TestData
# [1] "GOOD" "~" "からだに"
# [4] "出現順に番号を付ける" "同じ文字列" "GOOD"
# [7] "$" "KARAD" "同じ文字列"
# [10] "出現順に番号を付ける" "~" "GOOD"
# [13] "からだに" "$" "出現順に番号を付ける"
# [16] "からだに" "出現順に番号を付ける" "$"
# [19] "出現順に番号を付ける" "GOOD"
########
# 同じ文字列の出現順に番号を付けて一意にする:make_uniqueコマンド
# 文字列を指定:xオプション
# 文字列と番号の分割文字:sepオプション
# 番号をカッコで囲むかの設定:wrap_in_bracketsオプション;TRUE/FALSE
# 指定データが数字の場合に文字列に変換のエラー表示設定:warn_about_type_conversionオプション;TRUE/FALSE
make_unique(TestData, sep = "_", wrap_in_brackets = FALSE,
warn_about_type_conversion = TRUE)
# [1] "GOOD_1" "~_1" "からだに_1"
# [4] "出現順に番号を付ける_1" "同じ文字列_1" "GOOD_2"
# [7] "$_1" "KARAD" "同じ文字列_2"
# [10] "出現順に番号を付ける_2" "~_2" "GOOD_3"
# [13] "からだに_2" "$_2" "出現順に番号を付ける_3"
# [16] "からだに_3" "出現順に番号を付ける_4" "$_3"
# [19] "出現順に番号を付ける_5" "GOOD_4"
### 例えばこんな使い方 #####
# tidyverseパッケージがなければインストール
if(!require("tidyverse", quietly = TRUE)){
install.packages("tidyverse");require("tidyverse")
}
# 作業
TestData |>
# 番号付け
make_unique(sep = "_", wrap_in_brackets = FALSE,
warn_about_type_conversion = TRUE) |>
# tibble化
as_tibble() %>%
# "_"で分割
separate(value, c("Character", "Number"), "_") |>
# NumberのNAを0にして数値化
mutate(Number = replace_na(Number, "0"),
Number = as.numeric(Number)) |>
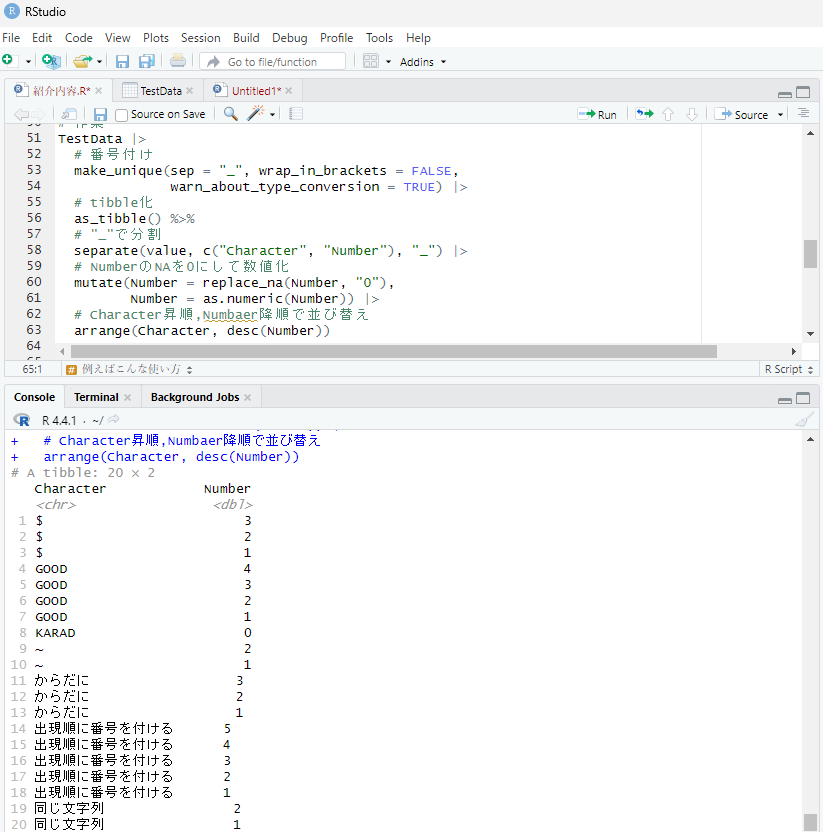
# Character昇順,Numbaer降順で並び替え
arrange(Character, desc(Number))
# separate(value, c("Character", "Number"), "_")処理警告が表示されるが問題なし
# A tibble: 20 × 2
# Character Number
# <chr> <dbl>
# 1 $ 3
# 2 $ 2
# 3 $ 1
# 4 GOOD 4
# 5 GOOD 3
# 6 GOOD 2
# 7 GOOD 1
# 8 KARAD 0
# 9 ~ 2
# 10 ~ 1
# 11 からだに 3
# 12 からだに 2
# 13 からだに 1
# 14 出現順に番号を付ける 5
# 15 出現順に番号を付ける 4
# 16 出現順に番号を付ける 3
# 17 出現順に番号を付ける 2
# 18 出現順に番号を付ける 1
# 19 同じ文字列 2
# 20 同じ文字列 1
# 警告メッセージ:
# Expected 2 pieces. Missing pieces filled with `NA` in 1 rows [8].
########少しでも、あなたの解析が楽になりますように!!